貝殼找房流量分發數據回收與治理演進之路 構建高效、可靠的數據處理服務
在數字化浪潮中,數據已成為驅動企業決策與業務增長的核心資產。對于貝殼找房這樣連接海量用戶、房源與經紀人的居住服務平臺而言,流量分發過程中的數據回收與治理,不僅是技術挑戰,更是保障平臺公平、效率與用戶體驗的戰略基石。本文將系統梳理貝殼找房在流量分發數據領域的處理服務演進之路,揭示其如何通過持續的數據治理,構建起高效、可靠的數據處理體系。
一、起點:數據回收的挑戰與初期實踐
貝殼找房的流量分發場景復雜,涉及搜索、推薦、列表頁等多個觸點,每天產生TB級的行為日志與業務數據。早期,數據回收面臨幾大核心挑戰:
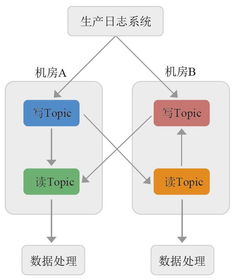
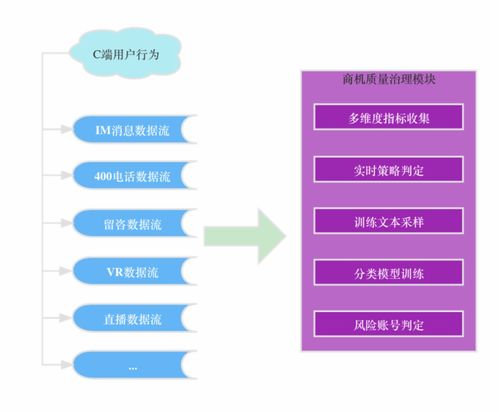
- 數據源分散:用戶點擊、瀏覽、轉化等行為數據分布在不同的客戶端與服務端,格式不一,采集鏈路存在丟數、延遲問題。
- 口徑不一致:業務方、產品與數據分析團隊對“曝光”、“點擊”、“有效流量”等關鍵指標定義存在分歧,導致數據可信度受損。
- 處理效率低下:批處理任務耗時漫長,無法支持實時或準實時的流量效果分析與策略調整。
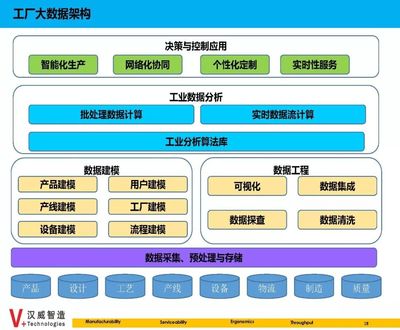
初期,團隊通過建立統一的SDK埋點規范、搭建基礎的Flink實時計算管道與Hive離線數倉,實現了數據從采集到可查詢的初步閉環,為后續治理奠定了基礎。
二、演進:體系化治理與平臺化服務
隨著業務規模擴張與精細化運營需求提升,簡單的數據管道已無法滿足要求。貝殼啟動了數據治理的體系化建設,核心演進方向包括:
- 元數據與數據質量治理:
- 建立全局數據字典,明確定義流量相關指標的業務含義、計算口徑與歸屬部門,實現“一處定義,處處一致”。
- 構建數據質量監控體系,在數據采集、傳輸、計算的關鍵節點設置校驗規則,對數據延遲、波動、缺失進行實時告警與自動修復,確保下游分析“源頭活水清”。
- 實時數倉與流批一體:
- 升級實時計算架構,引入Kafka、Flink、Doris等組件,構建低延遲的實時數倉。這使得流量分發效果(如新策略的CTR、CVR)能在分鐘級甚至秒級被感知,助力算法團隊快速迭代A/B實驗。
- 推動流批一體架構,同一套邏輯代碼可同時處理實時流與歷史批量數據,減少了維護成本,并保證了實時與離線數據結果的一致性。
- 構建自助式數據產品與服務:
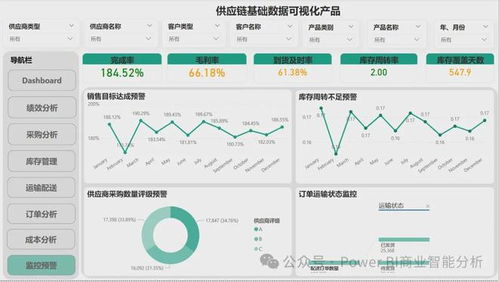
- 將處理后的標準化流量數據,通過數據中臺以API、數據集市或BI報表等形式,開放給業務、產品、算法等不同角色。例如,為運營人員提供流量漏斗看板,為算法工程師提供特征數據集,將數據能力產品化、服務化。
三、深化:智能驅動與價值閉環
當前,貝殼的流量分發數據處理服務已進入“智能驅動價值”的深化階段:
- 智能化治理:利用機器學習模型自動檢測數據異常、推斷數據血緣關系、優化存儲與計算資源,降低人工運維成本。
- 歸因分析與價值度量:構建復雜的歸因模型,精準量化不同渠道、不同策略對最終成交轉化的貢獻度,使流量分發的ROI評估更加科學,驅動預算與資源的精準投放。
- 反饋驅動迭代:形成“數據回收 -> 治理與分析 -> 策略優化 -> 效果評估 -> 數據再回收”的完整閉環。數據處理服務不僅被動響應需求,更主動洞察問題、提出優化建議,成為業務增長的“智慧引擎”。
四、未來展望
貝殼找房的數據處理服務將繼續向更實時、更智能、更安全的方向演進:探索邊緣計算以降低端到端延遲;深化AI在數據治理中的應用;加強數據安全與隱私計算能力,在合規前提下最大化數據價值。
****
貝殼找房的流量分發數據回收與治理之路,是一部從工具建設到體系構建,再到價值創造的演進史。它印證了一個道理:在數據洪流中,唯有通過持續、系統的治理,將原始數據轉化為可信、易用、智能的數據服務,才能真正釋放數據潛能,賦能業務在激烈的市場競爭中精準航行。這條演進之路,也為行業提供了可資借鑒的數據能力建設范本。
如若轉載,請注明出處:http://www.jwl7.cn/product/72.html
更新時間:2026-04-28 09:54:10